Saturday, November 18, 2017
FNDFS and FNDSM
application listener support two services FNDFS and FNDSM.
Apps Listener usually run on All Oracle Applications 11i Nodes with listener alias as APPS_$SID is mainly used for listening requests for services like FNDFS & FNDSM.
FNDFS or the Report Review Agent (RRA) is the default text viewer within Oracle Applications, which allows users to view report output and log files. Report Review Agent is also referred to by the executable FNDFS.
FNDSM is the Service manager. FNDSM is executable & core component in GSM ( Generic Service Management Framework ). You start FNDSM services via APPS listener on all Nodes in Application Tier.
Scenario where we can't see the output of Concurrent Requests:
check the fndwrr.exe size in production and compare it with Test Instance.
fndwrr.exe is present in $FND_TOP/bin
If there is any difference then relink the FNDFS executable.
adrelink.sh force=y "fnd FNDFS"
Apps Listener usually run on All Oracle Applications 11i Nodes with listener alias as APPS_$SID is mainly used for listening requests for services like FNDFS & FNDSM.
FNDFS or the Report Review Agent (RRA) is the default text viewer within Oracle Applications, which allows users to view report output and log files. Report Review Agent is also referred to by the executable FNDFS.
FNDSM is the Service manager. FNDSM is executable & core component in GSM ( Generic Service Management Framework ). You start FNDSM services via APPS listener on all Nodes in Application Tier.
Scenario where we can't see the output of Concurrent Requests:
check the fndwrr.exe size in production and compare it with Test Instance.
fndwrr.exe is present in $FND_TOP/bin
If there is any difference then relink the FNDFS executable.
adrelink.sh force=y "fnd FNDFS"
https://oraclehub.wordpress.com/2013/05/08/not-able-to-view-concurrent-request-output/
Application Patch
Bug Definition: A software bug is an error, flaw, failure, or fault in a computer program or system that produces an incorrect or unexpected result, or causes it to behave in unintended ways.
AD_BUGS:
Holds information about the various Oracle Applications bugs whose fixes have been applied (ie. patched) in the Oracle Applications installation.
AD_APPLIED_PATCHES:
Holds information about the "distinct" Oracle Applications patches that have been applied.
If 2 patches happen to have the same name but are different in content (eg. "merged" patches), then they are considered distinct and this table will therefore hold 2 records.
A patch can deliver solution for more than one bug, so ad_applied_patches may not give u the perfect information as in case of ad_bugs.
Difference:
AD_BUGS contains all bug numbers fixed on your system, while AD_APPLIED_PATCHES contains all patch numbers which were applied to your system only.
if you use merged patches, always check AD_BUGS.
select bug_number from ad_bugs where bug_number in ('&bug_number');
For example: if you apply 11.5.10 CU2, it will add a row with patch_name=3480000 to AD_APPLIED_PATCHES and it will insert thousands of entries in AD_BUGS (including 3480000).
What are the different types of patches?
oneoff, mini packs, family packs, maintanance packs, rollup pathches, colsolidated patches.
What is a oneoff patch?
An oneoff patch is a small patch of (20-90K size) without any pre-req’s
An one-off patch is a small patch (of without any pre-requisites) to fix a bug.
What is a mini pack ?
A mini pack is one which will upgrade any product patchset level to next level like AD.H to AD.I
What is Family pack ?
A Family pack is one which will upgade the patchset level of all the products in that family to perticular patchsetlevel.
What is Maintanance pack ?
A maintanance pack will upgrade applications from one version to another like 11.5.8 to 11.5.9
What is a Rollup patch?
A rollup patch is one which will deliver bug fixes identified after the release of any major application versions like 11.5.8/11.5.9
What is consilidated patch?
Consolidated patches will come into pictures after upgrades from one version of applications to anoter, all post upgrade patches will a consolidated and given as consolidated patch.
What are the tables adpatch will create and when?
Adpatch will create FND_INSTALL_PROCESSES and AD_DEFERRED_JOBS table when it will apply d,g and u drivers.
What is the significance of FND_INSTALL_PROCESSES and AD_DEFERRED_JOBS table?
FND_INSTALL_PROCESSES table will store the worker information like what job is assigned to which worker and its status.
AD_DEFERRED_JOBS will come into picture when some worker is failed, it will be moved to AD_DEFERRED_JOBS table, from where again adpatch will take that job and try to resign, after doing this 3 times if still that worker is failing, then adpatch will stop patching and throw the error that perticular worker has failed. We need to trouble shoot and restrart the worker.
While applying a patch if that patch is failing because of a pre-req then how you will apply that pre-req patch and resume with the current patch?
We need to take the backup of FND_INSTALL_PROCESSES and AD_DEFERRED_JOBS tables and restart directory at APPL_TOP/amdin/SID and then use adctrl to quit all the workers. Then apply the pre-req patch , after that rename u r restart directory to its original name and create FND_INSTALL_PROCESSES and AD_DEFERRED_JOBS tables from the bcakup tables. Start adpatch session and take the options want to continue previous session.
What is the significance of backup directory under u r patch directory?
When we apply a patch it will keep the copy of the files which its going to change in file system.
How adpatch will know the file versions of the patch delivered files?
With each patch a file with name f.ldt is delivered , which contain the file versions of the files dilivered with the patch. Adpatch will use this file to compare the file versions of files its delivering with the file on file system.
How adpatch knows what are the pre-req’s for the patch which it is applying?
With every patch a file called b.ldt file will be delivered which contain the pre-req information. adpatch load this into databse using FNDLOAD and check , whether those pre-req patches were applied or not.
What are the different modes you can run your adpatch?
1.Interactive – default mode
2.Non interactive – Use defaults files to store prompt values
(adpatch defaultsfile= interactive=no)
3. Test – Without actually applying a patch just to check what doing.(adpatch apply=no)
4. Pre-install – (adpatch preinstall=y)
This mode will be usefull to discrease upgrade downtime as its applies bus fixes without running SQL,EXEC and generate portion of patch.
Adpatch Reducing Patching Downtime:
Use a shared application-tier file system
Distribute worker processes across multiple servers
Merge multiple patches using AD Merge Patch
Run AD Patch in non-interactive mode
Defer system-wide database tasks until the end
Avoid resource-related bottlenecks
Increase batch size (Might result into negative )
adpatch options=noautoconfig
Checkfile
The chekfile option of adpatch tells adpathc to check for already executed exec, SQL, and exectier commands.
adpatch options=nocheckfile
Compile Database
By defaulty autopatch compiles the invalid objects after the patch application,
adpatch options=nocompiledb
Compile JSP
By defaulty autopatch compiles the java server pages (jsp) after the patch application,
adpatch options=nocompilejsp
adpatch options=nocopyportion
adpatch options=nodatabaseportion
adpatch options=nogenerateportion
Maintenance Mode
If you wish to apply a patch regardless of the system being in maintenance mode you can use options=hotpatch.
adpatch options=hotpatch
Pre requisite Patch Check
If you wish adpatch not to check for pre requisite patches before application of the main patch
adpatch options=noprereq
Maintain MRC
You can use the maintainmrc option to specify weather you wish adpatch to execute the Maintain MRC schema as a part of the patch application or not.
adpatch options=nomaintainmrc
Where would I find .rf9 file, and what exactly it does?
These files are used during restart of a patch in case of patch failure because of some reason.
What are .odf file in apps patch?
odf stands for Object Description Files used to create tables & other database objects while applying a patch.
What is .lgi file?
lgi files are created with patching along with .log files . .lgi files are informative log files containing information related to patch. You can check .lgi files to see what activities patch has done.
AD_BUGS:
Holds information about the various Oracle Applications bugs whose fixes have been applied (ie. patched) in the Oracle Applications installation.
AD_APPLIED_PATCHES:
Holds information about the "distinct" Oracle Applications patches that have been applied.
If 2 patches happen to have the same name but are different in content (eg. "merged" patches), then they are considered distinct and this table will therefore hold 2 records.
A patch can deliver solution for more than one bug, so ad_applied_patches may not give u the perfect information as in case of ad_bugs.
Difference:
AD_BUGS contains all bug numbers fixed on your system, while AD_APPLIED_PATCHES contains all patch numbers which were applied to your system only.
if you use merged patches, always check AD_BUGS.
select bug_number from ad_bugs where bug_number in ('&bug_number');
For example: if you apply 11.5.10 CU2, it will add a row with patch_name=3480000 to AD_APPLIED_PATCHES and it will insert thousands of entries in AD_BUGS (including 3480000).
What are the different types of patches?
oneoff, mini packs, family packs, maintanance packs, rollup pathches, colsolidated patches.
What is a oneoff patch?
An oneoff patch is a small patch of (20-90K size) without any pre-req’s
An one-off patch is a small patch (of without any pre-requisites) to fix a bug.
What is a mini pack ?
A mini pack is one which will upgrade any product patchset level to next level like AD.H to AD.I
What is Family pack ?
A Family pack is one which will upgade the patchset level of all the products in that family to perticular patchsetlevel.
What is Maintanance pack ?
A maintanance pack will upgrade applications from one version to another like 11.5.8 to 11.5.9
What is a Rollup patch?
A rollup patch is one which will deliver bug fixes identified after the release of any major application versions like 11.5.8/11.5.9
What is consilidated patch?
Consolidated patches will come into pictures after upgrades from one version of applications to anoter, all post upgrade patches will a consolidated and given as consolidated patch.
What are the tables adpatch will create and when?
Adpatch will create FND_INSTALL_PROCESSES and AD_DEFERRED_JOBS table when it will apply d,g and u drivers.
What is the significance of FND_INSTALL_PROCESSES and AD_DEFERRED_JOBS table?
FND_INSTALL_PROCESSES table will store the worker information like what job is assigned to which worker and its status.
AD_DEFERRED_JOBS will come into picture when some worker is failed, it will be moved to AD_DEFERRED_JOBS table, from where again adpatch will take that job and try to resign, after doing this 3 times if still that worker is failing, then adpatch will stop patching and throw the error that perticular worker has failed. We need to trouble shoot and restrart the worker.
While applying a patch if that patch is failing because of a pre-req then how you will apply that pre-req patch and resume with the current patch?
We need to take the backup of FND_INSTALL_PROCESSES and AD_DEFERRED_JOBS tables and restart directory at APPL_TOP/amdin/SID and then use adctrl to quit all the workers. Then apply the pre-req patch , after that rename u r restart directory to its original name and create FND_INSTALL_PROCESSES and AD_DEFERRED_JOBS tables from the bcakup tables. Start adpatch session and take the options want to continue previous session.
What is the significance of backup directory under u r patch directory?
When we apply a patch it will keep the copy of the files which its going to change in file system.
How adpatch will know the file versions of the patch delivered files?
With each patch a file with name f.ldt is delivered , which contain the file versions of the files dilivered with the patch. Adpatch will use this file to compare the file versions of files its delivering with the file on file system.
How adpatch knows what are the pre-req’s for the patch which it is applying?
With every patch a file called b.ldt file will be delivered which contain the pre-req information. adpatch load this into databse using FNDLOAD and check , whether those pre-req patches were applied or not.
What are the different modes you can run your adpatch?
1.Interactive – default mode
2.Non interactive – Use defaults files to store prompt values
(adpatch defaultsfile= interactive=no)
3. Test – Without actually applying a patch just to check what doing.(adpatch apply=no)
4. Pre-install – (adpatch preinstall=y)
This mode will be usefull to discrease upgrade downtime as its applies bus fixes without running SQL,EXEC and generate portion of patch.
Adpatch Reducing Patching Downtime:
Use a shared application-tier file system
Distribute worker processes across multiple servers
Merge multiple patches using AD Merge Patch
Run AD Patch in non-interactive mode
Defer system-wide database tasks until the end
Avoid resource-related bottlenecks
Increase batch size (Might result into negative )
adpatch options=noautoconfig
Checkfile
The chekfile option of adpatch tells adpathc to check for already executed exec, SQL, and exectier commands.
adpatch options=nocheckfile
Compile Database
By defaulty autopatch compiles the invalid objects after the patch application,
adpatch options=nocompiledb
Compile JSP
By defaulty autopatch compiles the java server pages (jsp) after the patch application,
adpatch options=nocompilejsp
adpatch options=nocopyportion
adpatch options=nodatabaseportion
adpatch options=nogenerateportion
Maintenance Mode
If you wish to apply a patch regardless of the system being in maintenance mode you can use options=hotpatch.
adpatch options=hotpatch
Pre requisite Patch Check
If you wish adpatch not to check for pre requisite patches before application of the main patch
adpatch options=noprereq
Maintain MRC
You can use the maintainmrc option to specify weather you wish adpatch to execute the Maintain MRC schema as a part of the patch application or not.
adpatch options=nomaintainmrc
Where would I find .rf9 file, and what exactly it does?
These files are used during restart of a patch in case of patch failure because of some reason.
What are .odf file in apps patch?
odf stands for Object Description Files used to create tables & other database objects while applying a patch.
What is .lgi file?
lgi files are created with patching along with .log files . .lgi files are informative log files containing information related to patch. You can check .lgi files to see what activities patch has done.
Wednesday, October 18, 2017
Enable user level debug.
These profile option should be rarely changed at Site level.
Profile Option Description
FND: Debug Log Enabled
Using this profile option, Logging of debug message can be turned ON or OFF. This profile is available at user level
FND: Debug Log Level
This profile describes what kind of message will be logged when logging is enabled. There are six level of logging. These levels are
Statement – Set log level to statement when you need to see how your code inside a procedure is flowing.
Procedure – Set log level to Procedure when you are interested in knowing the value of input and output parameters of a procedure
Event – This could be used when you want to check if certain event has taken place, Such as a button is pressed in a form.
Exception – This should be used when you want to log all the exception encountered by a particular module.
Error – This should be used when you want to log all the error encountered by a particular module.
Unexpected – This is used for logging all the unexpected condition
Profile Option Description
FND: Debug Log Enabled
Using this profile option, Logging of debug message can be turned ON or OFF. This profile is available at user level
FND: Debug Log Level
This profile describes what kind of message will be logged when logging is enabled. There are six level of logging. These levels are
Statement – Set log level to statement when you need to see how your code inside a procedure is flowing.
Procedure – Set log level to Procedure when you are interested in knowing the value of input and output parameters of a procedure
Event – This could be used when you want to check if certain event has taken place, Such as a button is pressed in a form.
Exception – This should be used when you want to log all the exception encountered by a particular module.
Error – This should be used when you want to log all the error encountered by a particular module.
Unexpected – This is used for logging all the unexpected condition
Saturday, October 14, 2017
How to enable local login when SSO configured.
select profile "Applications SSO Login Types" to local at that particular user level for which password wanted to change.
Later use FNDCPASS to change user.
Error while invoking main Menu
Issue:

Solution:
add
the following line to the CONTEXT_FILE and run autoconfig.
<sslterminator
oa_var="s_enable_sslterminator">#</sslterminator>
How to license a new product through OAM
1. Login to OAM
2. Click on Site Map (The link near Applications Dashboard link)
3. Click on License Manager
4. Under License heading, click Products
5. Click on blue plus icon of More options
6. Click on the radio button: License Applications Product
7. Click on continue button
8. You'll get a list of all the individual products
9. Check the box on the left of the product you want to license
10. Click on Next button
11. Click on Submit button
12. You'll get a message: Successfully licensed the selected product(s). Click OK
2. Click on Site Map (The link near Applications Dashboard link)
3. Click on License Manager
4. Under License heading, click Products
5. Click on blue plus icon of More options
6. Click on the radio button: License Applications Product
7. Click on continue button
8. You'll get a list of all the individual products
9. Check the box on the left of the product you want to license
10. Click on Next button
11. Click on Submit button
12. You'll get a message: Successfully licensed the selected product(s). Click OK
Monday, October 9, 2017
Difference Between Local Inventory and Global Inventory:
oraInventory:
The inventory is a very important part of the Oracle Universal Installer.
oraInventory is repository (directory) which store/records oracle software products & their oracle_homes location on a machine.
This Inventory now a days in XML format and called as XML Inventory where as in past it used to be in binary format & called as binary Inventory.
There are basically two kind of inventories,
One is Local Inventory (also called as Oracle Home Inventory) and other is Global Inventory (also called as Central Inventory).
1.Local Inventory:
There is one Local inventory per ORACLE_HOME.
Inventory inside each Oracle Home is called as local Inventory or oracle_home Inventory. This Inventory holds information to that oracle_home only.
(Local inventory is located in the Oracle Home, It contains the information relevant to its particular home. )
SOLUTION
The only solution for local inventory corruption is to re-install the software.
2.Global Inventory
The central inventory directory outside the ORACLE_HOME (Global Inventory)
This inventory stores information about.
All the Oracle software products installed on all ORACLE_HOMES on a machine,These products can be various oracle components like database, oracle application server, collaboration suite, soa suite, forms & reports or discoverer server.
Other non-oracle products such as Java Runtime env's (JRE)
This global Inventory location will be determined by file oraInst.loc in /etc/oraInst.loc (on Linux) or /var/opt/oracle/oraInst.loc (solaris).
If you want to see list of oracle products on machine check for file inventory.xml under ContentsXML.
Yes, we can have multiple Global Inventory on a machine but if your upgrading or applying patch then change Inventory Pointer oraInst.loc to respective location.
What to do if my Global Inventory is corrupted ?
We can recreate global Inventory on machine using Universal Installer and attach already Installed oracle home by option
cd $ORACLE_HOME/oui/bin
./runInstaller -silent -attachHome -invPtrLoc ./oraInst.loc ORACLE_HOME="<Oracle_Home_Location>" ORACLE_HOME_NAME="<Oracle_Home_Name>"
Where
ORACLE_HOME= /opt/oracle/tech/db/D400T/102
ORACLE_HOME_NAME provide any name
[oracle@host bin]$ ./runInstaller -silent -attachHome -invPtrLoc /opt/oracle/tech/db/TEST/102/oraInst.loc ORACLE_HOME="/opt/oracle/tech/db/TEST/102" ORACLE_HOME_NAME="ora10204"
./runInstaller -silent -attachHome -invPtrLoc /opt/oracle/tech/db/TEST/102/oraInst.loc ORACLE_HOME="/opt/oracle/tech/db/D400T/102" ORACLE_HOME_NAME="ora10204"
cd $ORACLE_HOME/oui/bin
% ./attachHome.sh
====
cd $ORACLE_HOME/oui/bin/
./runInstaller -silent -detachHome -local -noClusterEnabled -invPtrLoc $ORACLE_HOME/oraInst.loc -ignorePreReq ORACLE_HOME=$ORACLE_HOME ORACLE_HOME_NAME=TEST_HOME
The inventory is a very important part of the Oracle Universal Installer.
oraInventory is repository (directory) which store/records oracle software products & their oracle_homes location on a machine.
This Inventory now a days in XML format and called as XML Inventory where as in past it used to be in binary format & called as binary Inventory.
There are basically two kind of inventories,
One is Local Inventory (also called as Oracle Home Inventory) and other is Global Inventory (also called as Central Inventory).
1.Local Inventory:
There is one Local inventory per ORACLE_HOME.
Inventory inside each Oracle Home is called as local Inventory or oracle_home Inventory. This Inventory holds information to that oracle_home only.
(Local inventory is located in the Oracle Home, It contains the information relevant to its particular home. )
SOLUTION
The only solution for local inventory corruption is to re-install the software.
2.Global Inventory
The central inventory directory outside the ORACLE_HOME (Global Inventory)
This inventory stores information about.
All the Oracle software products installed on all ORACLE_HOMES on a machine,These products can be various oracle components like database, oracle application server, collaboration suite, soa suite, forms & reports or discoverer server.
Other non-oracle products such as Java Runtime env's (JRE)
This global Inventory location will be determined by file oraInst.loc in /etc/oraInst.loc (on Linux) or /var/opt/oracle/oraInst.loc (solaris).
If you want to see list of oracle products on machine check for file inventory.xml under ContentsXML.
Yes, we can have multiple Global Inventory on a machine but if your upgrading or applying patch then change Inventory Pointer oraInst.loc to respective location.
What to do if my Global Inventory is corrupted ?
We can recreate global Inventory on machine using Universal Installer and attach already Installed oracle home by option
cd $ORACLE_HOME/oui/bin
./runInstaller -silent -attachHome -invPtrLoc ./oraInst.loc ORACLE_HOME="<Oracle_Home_Location>" ORACLE_HOME_NAME="<Oracle_Home_Name>"
Where
ORACLE_HOME= /opt/oracle/tech/db/D400T/102
ORACLE_HOME_NAME provide any name
[oracle@host bin]$ ./runInstaller -silent -attachHome -invPtrLoc /opt/oracle/tech/db/TEST/102/oraInst.loc ORACLE_HOME="/opt/oracle/tech/db/TEST/102" ORACLE_HOME_NAME="ora10204"
./runInstaller -silent -attachHome -invPtrLoc /opt/oracle/tech/db/TEST/102/oraInst.loc ORACLE_HOME="/opt/oracle/tech/db/D400T/102" ORACLE_HOME_NAME="ora10204"
cd $ORACLE_HOME/oui/bin
% ./attachHome.sh
====
cd $ORACLE_HOME/oui/bin/
./runInstaller -silent -detachHome -local -noClusterEnabled -invPtrLoc $ORACLE_HOME/oraInst.loc -ignorePreReq ORACLE_HOME=$ORACLE_HOME ORACLE_HOME_NAME=TEST_HOME
===
cd $ORACLE_HOME/clone/bin
perl clone.pl ORACLE_HOME=/oracle/product/11.2.0.3/TEST ORACLE_HOME_NAME=TEST_HOME ORACLE_BASE=/oracle/admin/TEST '-O"LOCAL_NODES=host-pdv-vm-251"' '-O"CLUSTER_NODES={host-pdv-vm-251}"'
Friday, October 6, 2017
ASM
Automatic Storage Management (ASM):
Automatic Storage Management (ASM) is a new feature that has be introduced in Oracle 10g to simplify the storage of Oracle datafiles, controlfiles and logfiles.Automatic Storage Management (ASM) is an integrated file system and volume manager expressly built for Oracle database files.
An Oracle ASM instance is built on the same technology as an Oracle Database instance. An Oracle ASM instance has a System Global Area (SGA) and background processes that are similar to those of Oracle Database. However, because Oracle ASM performs fewer tasks than a database, an Oracle ASM SGA is much smaller than a database SGA. In addition, Oracle ASM has a minimal performance effect on a server. Oracle ASM instances mount disk groups to make Oracle ASM files available to database instances; Oracle ASM instances do not mount databases.
Name | Description |
INSTANCE_TYPE | Must be set to ASM Note: This is the only required parameter. All other parameters take suitable defaults for most environments. |
ASM_POWER_LIMIT | The default power for disk rebalancing. Default: 1, Range: 0 – 11 |
ASM_DISKSTRING | A comma-separated list of strings that limits the set of disks that ASM discovers. May include wildcard characters. Only disks that match one of the strings are discovered. String format depends on the ASM library in use and on the operating system. The standard system library for ASM supports glob pattern matching. For example, on a Solaris server that does not use ASMLib, to limit discovery to disks that are in the /dev/rdsk/ directory, ASM_DISKSTRING would be set to: /dev/rdsk/* another example: /dev/rdsk/*s3,/dev/rdsk/*s4 (This could be simplified to:) /dev/rdsk/*s[34] Default: NULL. A NULL value causes ASM to search a default path for all disks in the system to which the ASM instance has read/write access. The default search path is platform-specific. |
ASM_DISKGROUPS | A list of the names of disk groups to be mounted by an ASM instance at startup, or when the ALTER DISKGROUP ALL MOUNT statement is used. Default: NULL (If this parameter is not specified, then no disk groups are mounted.) This parameter is dynamic, and if you are using a server parameter file (SPFILE), you should not need to manually alter this value. ASM automatically adds a disk group to this parameter when the disk group is successfully created or mounted, and automatically removes a disk group from this parameter when the disk group is dropped or dismounted. |
Disk Groups:
The primary component of ASM is the disk group. A disk group consists of a grouping of disks that are managed together as a unit.
Disks:
The physical disks are known as ASM disks, while the files that reside on the disks are know as ASM files.The disks in a disk group are referred to as ASM disks. On Windows operating systems, an ASM disk is always a partition.
When an ASM instance starts, it automatically discovers all available ASM disks.Discovery is the process of determining every disk device to which the ASM instance has been given I/O permissions (by some operating system mechanism), and of examining the contents of the first block of such disks to see if they are recognized as belonging to a disk group. ASM discovers disks in the paths that are listed in an initialization parameter, or if the parameter is NULL, in an operating system–dependent default path.
There are three types of ASM disk groups:
* Normal redundancy
* High redundancy
* External redundancy
The redundancy level controls how many disk failures are tolerated without dismounting the disk group or losing data.The default disk group type is normal redundancy.
NORMAL REDUNDANCY - Two-way mirroring, requiring two failure groups.
HIGH REDUNDANCY - Three-way mirroring, requiring three failure groups.
EXTERNAL REDUNDANCY - No mirroring for disks that are already protected using hardware mirroring or RAID. If you have hardware RAID it should be used in preference to ASM redundancy, so this will be the standard option for most installations.
External redundancy
Oracle ASM does not provide mirroring redundancy and relies on the storage system to provide RAID functionality. Any write error causes a forced dismount of the disk group. All disks must be located to successfully mount the disk group.
An external redundancy disk group cannot tolerate the failure of any disks in the disk group. Any kind of disk failure causes ASM to dismount the disk group.
Normal redundancy
Oracle ASM provides two-way mirroring by default, which means that all files are mirrored so that there are two copies of every extentOpens a new window. A loss of one Oracle ASM disk is tolerated. You can optionally choose three-way or unprotected mirroring.
A file specified with HIGH redundancy (three-way mirroring) in a NORMAL redundancy disk group provides additional protection from a bad disk sector, not protection from a disk failure.
A normal redundancy disk group can tolerate the failure of one failure group. If only one failure group fails, the disk group remains mounted and serviceable, and ASM performs a rebalance of the surviving disks (including the surviving disks in the failed failure group) to restore redundancy for the data in the failed disks. If more than one failure group fails, ASM dismounts the disk group.
High redundancy
Oracle ASM provides triple mirroring by default. A loss of two Oracle ASM disks in different failure groups is tolerated.
A high redundancy disk group can tolerate the failure of two failure groups. If one or two failure groups fail, the disk group remains mounted and serviceable, and ASM performs a rebalance of the surviving disks to restore redundancy for the data in the failed disks. If more than two failure groups fail, ASM dismounts the disk group.
If you specify mirroring for a file, then Oracle ASM automatically stores redundant copies of the file extents in separate failure groups.
****Query the v$osm_alias data dictionary view to see assigned alias names for ASM files.
ASM provides the following benefits:
Striping—ASM spreads data evenly across all disks in a disk group to optimize performance and utilization. This even distribution of database files eliminates the need for regular monitoring and I/O performance tuning.
Mirroring—ASM can increase availability by optionally mirroring any file. ASM mirrors at the file level, unlike operating system mirroring, which mirrors at the disk level. Mirroring means keeping redundant copies, or mirrored copies, of each extent of the file, to help avoid data loss caused by disk failures. The mirrored copy of each file extent is always kept on a different disk from the original copy. If a disk fails, ASM can continue to access affected files by accessing mirrored copies on the surviving disks in the disk group.
ASM supports 2-way mirroring, where each file extent gets one mirrored copy, and 3-way mirroring, where each file extent gets two mirrored copies.
ASM REBALANCING:
ASM permits you to add or remove disks from your disk storage system while the database is operating. When you add a disk, ASM automatically redistributes the data so that it is evenly spread across all disks in the disk group, including the new disk. This redistribution is known as rebalancing. It is done in the background and with minimal impact to database performance. When you request to remove a disk, ASM first rebalances by evenly relocating all file extents from the disk being removed to the other disks in the disk group.
ASM enables you to change the storage configuration without having to take the database offline. It automatically rebalances—redistributes file data evenly across all the disks of the disk group—after you add disks to or drop disks from a disk group.
Effects of Adding and Dropping Disks from a Disk Group
ASM automatically rebalances whenever disks are added or dropped. For a normal drop operation (without the FORCE option), a disk is not released from a disk group until data is moved off of the disk through rebalancing. Likewise, a newly added disk cannot support its share of the I/O workload until rebalancing completes. It is more efficient to add or drop multiple disks at the same time so that they are rebalanced as a single operation. This avoids unnecessary movement of data.
For a drop operation, when rebalance is complete, ASM takes the disk offline momentarily, and then drops it, setting disk header status to FORMER.
You can add or drop disks without shutting down the database. However, a performance impact on I/O activity may result.
Tuning Rebalance Operations
The V$ASM_OPERATION view provides information that can be used for adjusting ASM_POWER_LIMIT and the resulting power of rebalance operations. The V$ASM_OPERATION view also gives an estimate in the EST_MINUTES column of the amount of time remaining for the rebalance operation to complete. You can see the effect of changing the rebalance power by observing the change in the time estimate.
SET pagesize 299
SET lines 2999
SELECT GROUP_NUMBER,
OPERATION,
STATE,
POWER,
ACTUAL,
ACTUAL,
EST_MINUTES
FROM gv$asm_operation;
***==========================***
There are seven new v$ views provided in Oracle Database to monitor ASM structures.
v$asm_diskgroup:
v$asm_client:
V$ASM_DISK
v$asm_file:
v$asm_template:
v$asm_alias:
v$asm_operation:
Grip Version:
+++++++++++++
crsctl query crs activeversion
crsctl query crs activeversion
Mount and unmount diskgroup:
sqlplus / as sysasm
alter diskgroup DG_PDBPROD_AR mount;
alter diskgroup DG_PDBPROD_AR dismount;
select name,state,total_mb from v$asm_diskgroup;
select name,state from v$asm_diskgroup;
v$asm_diskgroup:
v$asm_client:
V$ASM_DISK
v$asm_file:
v$asm_template:
v$asm_alias:
v$asm_operation:
Grip Version:
+++++++++++++
crsctl query crs activeversion
crsctl query crs activeversion
Mount and unmount diskgroup:
sqlplus / as sysasm
alter diskgroup DG_PDBPROD_AR mount;
alter diskgroup DG_PDBPROD_AR dismount;
select name,state,total_mb from v$asm_diskgroup;
select name,state from v$asm_diskgroup;
SQL> select g.name disk_grp, o.group_number, operation , est_minutes from gv$asm_operation o, gv$asm_diskgroup g
where g.group_number = o.group_number and o.inst_id = g.inst_id;
no rows selected --> No rebalance operation in progress
SQL> select d.inst_id, dg.name dg_name, dg.state dg_state, dg.type,d.name, d.DISK_NUMBER dsk_no, d.MOUNT_STATUS, d.HEADER_STATUS, d.MODE_STATUS,
d.STATE, d. PATH, d.FAILGROUP FROM GV$ASM_DISK d, gv$asm_diskgroup dg
where dg.group_number(+)=d.group_number and d.inst_id = dg.inst_id order by d.inst_id, d.group_number;
Add disk group:
sqlplus / as sysasm
alter diskgroup <diskgroup_name> add disk 'ORCL:<disk_name>';
alter diskgroup DG_BRMDEV2_DT01 add disk 'ORCL:D2BRM_DT01_106G_003';
srvctl add asm
srvctl start asm
crsctl status resource -t
Difference between CANDIDATE & PROVISIONED in ASM DISK
Disks that were discovered but that have not yet been assigned to a disk group have a header status of either CANDIDATE or PROVISIONED.
Below are the HEADER_STATUS in the v$ASM_DISK. I have taken below status from 11gR2.
UNKNOWN - Automatic Storage Management disk header has not been read
CANDIDATE - Disk is not part of a disk group and may be added to a disk group with the ALTER DISKGROUP statement
INCOMPATIBLE - Version number in the disk header is not compatible with the Automatic Storage Management software version.
PROVISIONED - Disk is not part of a disk group and may be added to a disk group with the ALTER DISKGROUP statement. The PROVISIONED header status is different from the CANDIDATE header status in that PROVISIONED implies that an additional platform-specific action has been taken by an administrator to make the disk available for Automatic Storage Management.
MEMBER - Disk is a member of an existing disk group. No attempt should be made to add the disk to a different disk group. The ALTER DISKGROUP statement will reject such an addition unless overridden with the FORCE option
FORMER - Disk was once part of a disk group but has been dropped cleanly from the group. It may be added to a new disk group with the ALTER DISKGROUP statement.
CONFLICT - Automatic Storage Management disk was not mounted due to a conflict
FOREIGN - Disk contains data created by an Oracle product other than ASM. This includes datafiles, logfiles, and OCR disks.
When adding a disk, the FORCE option must be used if Oracle ASM recognizes that the disk was managed by Oracle. Such a disk appears in the V$ASM_DISK view with a status of FOREIGN.
The v$ views for ASM are built upon several ASM fixed tables, called x$ tables. The x$ tables are not really tables, they are C language structures inside the SGA RAM heap:

Script:
REM ASM views:
REM VIEW |ASM INSTANCE |DB INSTANCE
REM ----------------------------------------------------------------------------------------------------------
REM V$ASM_DISKGROUP |Describes a disk group (number, name, size |Contains one row for every open ASM
REM |related info, state, and redundancy type) |disk in the DB instance.
REM V$ASM_CLIENT |Identifies databases using disk groups |Contains no rows.
REM |managed by the ASM instance. |
REM V$ASM_DISK |Contains one row for every disk discovered |Contains rows only for disks in the
REM |by the ASM instance, including disks that |disk groups in use by that DB instance.
REM |are not part of any disk group. |
REM V$ASM_FILE |Contains one row for every ASM file in every |Contains rows only for files that are
REM |disk group mounted by the ASM instance. |currently open in the DB instance.
REM V$ASM_TEMPLATE |Contains one row for every template present in |Contains no rows.
REM |every disk group mounted by the ASM instance. |
REM V$ASM_ALIAS |Contains one row for every alias present in |Contains no rows.
REM |every disk group mounted by the ASM instance. |
REM v$ASM_OPERATION |Contains one row for every active ASM long |Contains no rows.
REM |running operation executing in the ASM instance. |
set wrap off
set lines 155 pages 9999
col "Group Name" for a6 Head "Group|Name"
col "Disk Name" for a10
col "State" for a10
col "Type" for a10 Head "Diskgroup|Redundancy"
col "Total GB" for 9,990 Head "Total|GB"
col "Free GB" for 9,990 Head "Free|GB"
col "Imbalance" for 99.9 Head "Percent|Imbalance"
col "Variance" for 99.9 Head "Percent|Disk Size|Variance"
col "MinFree" for 99.9 Head "Minimum|Percent|Free"
col "MaxFree" for 99.9 Head "Maximum|Percent|Free"
col "DiskCnt" for 9999 Head "Disk|Count"
prompt
prompt ASM Disk Groups
prompt ===============
SELECT g.group_number "Group"
, g.name "Group Name"
, g.state "State"
, g.type "Type"
, g.total_mb/1024 "Total GB"
, g.free_mb/1024 "Free GB"
, 100*(max((d.total_mb-d.free_mb)/d.total_mb)-min((d.total_mb-d.free_mb)/d.total_mb))/max((d.total_mb-d.free_mb)/d.total_mb) "Imbalance"
, 100*(max(d.total_mb)-min(d.total_mb))/max(d.total_mb) "Variance"
, 100*(min(d.free_mb/d.total_mb)) "MinFree"
, 100*(max(d.free_mb/d.total_mb)) "MaxFree"
, count(*) "DiskCnt"
FROM v$asm_disk d, v$asm_diskgroup g
WHERE d.group_number = g.group_number and
d.group_number <> 0 and
d.state = 'NORMAL' and
d.mount_status = 'CACHED'
GROUP BY g.group_number, g.name, g.state, g.type, g.total_mb, g.free_mb
ORDER BY 1;
prompt ASM Disks In Use
prompt ================
col "Group" for 999
col "Disk" for 999
col "Header" for a9
col "Mode" for a8
col "State" for a8
col "Created" for a10 Head "Added To|Diskgroup"
--col "Redundancy" for a10
--col "Failure Group" for a10 Head "Failure|Group"
col "Path" for a19
--col "ReadTime" for 999999990 Head "Read Time|seconds"
--col "WriteTime" for 999999990 Head "Write Time|seconds"
--col "BytesRead" for 999990.00 Head "GigaBytes|Read"
--col "BytesWrite" for 999990.00 Head "GigaBytes|Written"
col "SecsPerRead" for 9.000 Head "Seconds|PerRead"
col "SecsPerWrite" for 9.000 Head "Seconds|PerWrite"
select group_number "Group"
, disk_number "Disk"
, header_status "Header"
, mode_status "Mode"
, state "State"
, create_date "Created"
--, redundancy "Redundancy"
, total_mb/1024 "Total GB"
, free_mb/1024 "Free GB"
, name "Disk Name"
--, failgroup "Failure Group"
, path "Path"
--, read_time "ReadTime"
--, write_time "WriteTime"
--, bytes_read/1073741824 "BytesRead"
--, bytes_written/1073741824 "BytesWrite"
, read_time/reads "SecsPerRead"
, write_time/writes "SecsPerWrite"
from v$asm_disk_stat
where header_status not in ('FORMER','CANDIDATE')
order by group_number
, disk_number
/
Prompt File Types in Diskgroups
Prompt ========================
col "File Type" for a16
col "Block Size" for a5 Head "Block|Size"
col "Gb" for 9990.00
col "Files" for 99990
break on "Group Name" skip 1 nodup
select g.name "Group Name"
, f.TYPE "File Type"
, f.BLOCK_SIZE/1024||'k' "Block Size"
, f.STRIPED
, count(*) "Files"
, round(sum(f.BYTES)/(1024*1024*1024),2) "Gb"
from v$asm_file f,v$asm_diskgroup g
where f.group_number=g.group_number
group by g.name,f.TYPE,f.BLOCK_SIZE,f.STRIPED
order by 1,2;
clear break
prompt Instances currently accessing these diskgroups
prompt ==============================================
col "Instance" form a8
select c.group_number "Group"
, g.name "Group Name"
, c.instance_name "Instance"
from v$asm_client c
, v$asm_diskgroup g
where g.group_number=c.group_number
/
prompt Free ASM disks and their paths
prompt ==============================
col "Disk Size" form a9
select header_status "Header"
, mode_status "Mode"
, path "Path"
, lpad(round(os_mb/1024),7)||'Gb' "Disk Size"
from v$asm_disk
where header_status in ('FORMER','CANDIDATE')
order by path
/
prompt Current ASM disk operations
prompt ===========================
select *
from v$asm_operation
/
This is how some of the changes look
Added To Total Free Seconds Seconds
Group Disk Header Mode State Diskgroup GB GB Disk Name Path PerRead PerWrite
----- ---- --------- -------- -------- ---------- ------ ------ ---------- ------------------- ------- --------
1 0 MEMBER ONLINE NORMAL 20-FEB-09 89 88 FRA_0000 /dev/oracle/disk388 .004 .002
1 1 MEMBER ONLINE NORMAL 31-MAY-10 89 88 FRA_0001 /dev/oracle/disk260 .002 .002
1 2 MEMBER ONLINE NORMAL 31-MAY-10 89 88 FRA_0002 /dev/oracle/disk260 .007 .002
2 15 MEMBER ONLINE NORMAL 04-MAR-10 89 29 DATA_0015 /dev/oracle/disk203 .012 .023
2 16 MEMBER ONLINE NORMAL 04-MAR-10 89 29 DATA_0016 /dev/oracle/disk203 .012 .021
2 17 MEMBER ONLINE NORMAL 04-MAR-10 89 29 DATA_0017 /dev/oracle/disk203 .007 .026
2 27 MEMBER ONLINE NORMAL 31-MAY-10 89 29 DATA_0027 /dev/oracle/disk260 .011 .023
2 28 MEMBER ONLINE NORMAL 31-MAY-10 89 29 DATA_0028 /dev/oracle/disk259 .009 .020
2 38 MEMBER ONLINE NORMAL 31-MAY-10 89 29 DATA_0038 /dev/oracle/disk190 .012 .025
2 39 MEMBER ONLINE NORMAL 31-MAY-10 89 29 DATA_0039 /dev/oracle/disk189 .014 .015
2 40 MEMBER ONLINE NORMAL 31-MAY-10 89 30 DATA_0040 /dev/oracle/disk260 .011 .024
2 41 MEMBER ONLINE NORMAL 31-MAY-10 89 30 DATA_0041 /dev/oracle/disk260 .009 .022
2 42 MEMBER ONLINE NORMAL 31-MAY-10 89 29 DATA_0042 /dev/oracle/disk260 .011 .018
2 43 MEMBER ONLINE NORMAL 31-MAY-10 89 29 DATA_0043 /dev/oracle/disk260 .003 .026
2 44 MEMBER ONLINE NORMAL 31-MAY-10 89 29 DATA_0044 /dev/oracle/disk260 .008 .019
2 45 MEMBER ONLINE NORMAL 31-MAY-10 89 30 DATA_0045 /dev/oracle/disk193 .008 .018
2 46 MEMBER ONLINE NORMAL 31-MAY-10 89 30 DATA_0046 /dev/oracle/disk192 .007 .024
2 47 MEMBER ONLINE NORMAL 31-MAY-10 89 30 DATA_0047 /dev/oracle/disk191 .005 .022
2 48 MEMBER ONLINE NORMAL 31-MAY-10 89 29 DATA_0048 /dev/oracle/disk190 .008 .021
2 49 MEMBER ONLINE NORMAL 31-MAY-10 89 29 DATA_0049 /dev/oracle/disk189 .008 .026
2 50 MEMBER ONLINE NORMAL 31-MAY-10 89 29 DATA_0050 /dev/oracle/disk261 .009 .030
56 rows selected.
File Types in Diskgroups
========================
Group Block
Name File Type Size STRIPE Files Gb
------ ---------------- ----- ------ ------ --------
DATA CONTROLFILE 16k FINE 1 0.01
DATAFILE 16k COARSE 404 2532.58
ONLINELOG 1k FINE 3 6.00
PARAMETERFILE 1k COARSE 1 0.00
TEMPFILE 16k COARSE 13 440.59
FRA AUTOBACKUP 16k COARSE 2 0.02
CONTROLFILE 16k FINE 1 0.01
ONLINELOG 1k FINE 3 6.00
Refrences:
https://www.oracle.com/technical-resources/articles/database/sql-11g-asm.html
Saturday, September 23, 2017
error while loading create database character set
Oracle instance shut down
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: failure of Duplicate Db command at 07/14/2017 10:43:34
RMAN-05501: aborting duplication of target database
RMAN-03015: error occurred in stored script Memory Script
RMAN-06136: ORACLE error from auxiliary database: ORA-12709: error while loading create database character set
Recovery Manager complete.
[oracle@host old]$ perl $ORACLE_HOME/nls/data/old/cr9idata.pl
Creating directory /u01/app/oracle/EBS/TEST/12.1.0.2/db1/nls/data/9idata ...
Copying files to /u01/app/oracle/EBS/TEST/12.1.0.2/db1/nls/data/9idata...
Copy finished.
Please reset environment variable ORA_NLS10 to /u01/app/oracle/EBS/TEST/12.1.0.2/db1/nls/data/9idata!
[oracle@host old]$
RMAN-00571: ===========================================================
RMAN-00569: =============== ERROR MESSAGE STACK FOLLOWS ===============
RMAN-00571: ===========================================================
RMAN-03002: failure of Duplicate Db command at 07/14/2017 10:43:34
RMAN-05501: aborting duplication of target database
RMAN-03015: error occurred in stored script Memory Script
RMAN-06136: ORACLE error from auxiliary database: ORA-12709: error while loading create database character set
Recovery Manager complete.
[oracle@host old]$ perl $ORACLE_HOME/nls/data/old/cr9idata.pl
Creating directory /u01/app/oracle/EBS/TEST/12.1.0.2/db1/nls/data/9idata ...
Copying files to /u01/app/oracle/EBS/TEST/12.1.0.2/db1/nls/data/9idata...
Copy finished.
Please reset environment variable ORA_NLS10 to /u01/app/oracle/EBS/TEST/12.1.0.2/db1/nls/data/9idata!
[oracle@host old]$
Thursday, August 31, 2017
Wait Events
Information about wait events is displayed in three dynamic performance views:
V$SESSION_WAIT displays the events for which sessions have just completed waiting or are currently waiting.
V$SYSTEM_EVENT displays the total number of times all the sessions have waited for the events in that view.
V$SESSION_EVENT is similar to V$SYSTEM_EVENT, but displays all waits for each session.
set lines 120 trimspool on
col event head "Waited for" format a30
col total_waits head "Total|Waits" format 999,999
col tw_ms head "Waited|for (ms)" format 999,999.99
col aw_ms head "Average|Wait (ms)" format 999,999.99
col mw_ms head "Max|Wait (ms)" format 999,999.99
select event, total_waits, time_waited*10 tw_ms,
average_wait*10 aw_ms, max_wait*10 mw_ms
from v$session_event
where sid = 37
Waits caused by I/O related performance issues:
db file sequential read
db file scattered read
direct path read
direct path read temp
direct path write temp
free buffer wait
log file sync
Scattered read /Sequential read:
DB File scattered read wait event occurs when an oracle process waits for a physical read of multiple oracle blocks from the disk. This wait identifies that a full scan (Full Table Scan or Index fast full scan).
when a SQL Statement causes a full scan, oracle’s shadow process reads up to DB_FILE_MULTIBLOCK_READ_COUNT consecutive blocks at a time and scatters them into buffers in the buffer cache. Since a large no. of blocks have to be read into the buffer cache, server process has to search for a large no. of free/usable blocks in buffer cache which leads to wait included in db file scattered read wait.
A db file scattered read is the same type of event as "db file sequential read", except that Oracle will read multiple data blocks. Multi-block reads are typically used on full table scans.
db file scattered read => full table scan, index fast full scan
db file sequential:
This event represents a wait for a physical read of a single Oracle block from the disk.
db file sequential read is a single block IO, most typically these comes from index range scans and table access by index rowid.
db file sequential read => index scan, table access by index rowid.
V$SESSION_WAIT displays the events for which sessions have just completed waiting or are currently waiting.
V$SYSTEM_EVENT displays the total number of times all the sessions have waited for the events in that view.
V$SESSION_EVENT is similar to V$SYSTEM_EVENT, but displays all waits for each session.
set lines 120 trimspool on
col event head "Waited for" format a30
col total_waits head "Total|Waits" format 999,999
col tw_ms head "Waited|for (ms)" format 999,999.99
col aw_ms head "Average|Wait (ms)" format 999,999.99
col mw_ms head "Max|Wait (ms)" format 999,999.99
select event, total_waits, time_waited*10 tw_ms,
average_wait*10 aw_ms, max_wait*10 mw_ms
from v$session_event
where sid = 37
Waits caused by I/O related performance issues:
db file sequential read
db file scattered read
direct path read
direct path read temp
direct path write temp
free buffer wait
log file sync
Scattered read /Sequential read:
DB File scattered read wait event occurs when an oracle process waits for a physical read of multiple oracle blocks from the disk. This wait identifies that a full scan (Full Table Scan or Index fast full scan).
when a SQL Statement causes a full scan, oracle’s shadow process reads up to DB_FILE_MULTIBLOCK_READ_COUNT consecutive blocks at a time and scatters them into buffers in the buffer cache. Since a large no. of blocks have to be read into the buffer cache, server process has to search for a large no. of free/usable blocks in buffer cache which leads to wait included in db file scattered read wait.
A db file scattered read is the same type of event as "db file sequential read", except that Oracle will read multiple data blocks. Multi-block reads are typically used on full table scans.
db file scattered read => full table scan, index fast full scan
db file sequential:
This event represents a wait for a physical read of a single Oracle block from the disk.
db file sequential read is a single block IO, most typically these comes from index range scans and table access by index rowid.
db file sequential read => index scan, table access by index rowid.
db file sequential read (single block read into one SGA buffer)
db file scattered read (multiblock read into many discontinuous SGA buffers
direct read (single or multiblock read into the PGA, bypassing the SGA)
db file sequential reads:
Possible Causes:
Unselective index use.
Fragmented Indexes.
High I/O on a particular disk or mount point.
Bad application design.
Index reads performance can be affected by slow I/O subsystem and/or poor database files layout, which result in a higher average wait time
Action:
Check indexes on the table to ensure that the right index is being used
Check the column order of the index with the WHERE clause of the Top SQL statements
Rebuild indexes with a high clustering factor
Use partitioning to reduce the amount of blocks being visited
Make sure optimizer statistics are up to date
Relocate ‘hot’ datafiles
Consider the usage of multiple buffer pools and cache frequently used indexes/tables in the KEEP pool.
Inspect the execution plans of the SQL statements that access data through indexes
Is it appropriate for the SQL statements to access data through index lookups?
Is the application an online transaction processing (OLTP) or decision support system (DSS)?
Would full table scans be more efficient?
Do the statements use the right driving table?
The optimization goal is to minimize both the number of logical and physical I/Os.
db file scattered reads:
Possible Causes:
The Oracle session has requested and is waiting for multiple contiguous database blocks (up to DB_FILE_MULTIBLOCK_READ_COUNT) to be read into the SGA from disk.
Full Table scans
Fast Full Index Scans
Actions:
Optimize multi-block I/O by setting the parameter DB_FILE_MULTIBLOCK_READ_COUNT
Partition pruning to reduce number of blocks visited
Consider the usage of multiple buffer pools and cache frequently used indexes/tables in the KEEP pool
Optimize the SQL statement that initiated most of the waits. The goal is to minimize the number of physical and logical reads.
Should the statement access the data by a full table scan or index FFS?
Would an index range or unique scan be more efficient?
Does the query use the right driving table?
Are the SQL predicates appropriate for hash or merge join?
If full scans are appropriate, can parallel query improve the response time?
The objective is to reduce the demands for both the logical and physical I/Os, and this is best achieved through SQL and application tuning.
Make sure all statistics are representative of the actual data. Check the LAST_ANALYZED date
PL/SQL lock timer:
Wait event is called through the DBMSLOCK.SLEEP or USERLOCK.SLEEP procedure. This event will most likely originate from procedures written by a user.
SELECT vs.osuser,vw.event,vw.p1,vw.p2,vw.p3 ,vt.sql_text , vs.program
FROM gv$session_wait vw, gv$sqltext vt , gv$session vs
WHERE vw.event = 'PL/SQL lock timer'
AND vt.address=vs.sql_address
AND vs.inst_id = vw.inst_id
AND vs.sid = vw.sid;
Busy Buffer waits:
Buffer busy wait happens when a session wants to access a database block in the buffer cache but it cannot as the buffer is “busy”. There are mainly two cases where this can occur are:
1.Another session is reading the block into the buffer
2.Another session holds the buffer in an incompatible mode to our request
This means that the queries are waiting for the blocks to be read into the db cache.there could be reason when the block may be busy in the cache and session is waiting for it.It could be undo/data block or segment header wait.
Select p1 "File #",p2 "Block #",p3 "Reason Code" from v$session_wait Where event = 'buffer busy waits';
Select owner, segment_name, segment_type from dba_extents Where file_id = &P1 and &P2 between block_id and block_id + blocks -1;
Possible Causes:
Buffer busy waits are common in an I/O-bound Oracle system.
The two main cases where this can occur are:
Another session is reading the block into the buffer
Another session holds the buffer in an incompatible mode to our request
These waits indicate read/read, read/write,or write/write contention.
The Oracle session is waiting to pin a buffer.
A buffer must be pinned before it can be read or modified. Only one process can pin a buffer at any one time.
This wait can be intensified by a large block size as more rows can be contained within the block
This wait happens when a session wants to access a database block in the buffer cache but it cannot as the buffer is "busy
It is also often due to several processes repeatedly reading the same blocks (eg: if lots of people scan the same index or datablock)
Actions:
The main way to reduce buffer busy waits is to reduce the total I/O on the system
Depending on the block type, the actions will differ
Data Blocks
Eliminate HOT blocks from the application.
Check for repeatedly scanned / unselective indexes.
Try rebuilding the object with a higher PCTFREE so that you reduce the number of rows per block.
Check for 'right- hand-indexes' (indexes that get inserted into at the same point by many processes).
Increase INITRANS and MAXTRANS and reduce PCTUSED This will make the table less dense .
Reduce the number of rows per block
Segment Header
Increase of number of FREELISTs and FREELIST GROUPs
Undo Header
Increase the number of Rollback Segments.
log file sync:
A user session issuing a commit command must wait until the LGWR (Log Writer) process writes the log entries associated with the user transaction to the log file on the disk. Oracle must commit the transaction’s entries to disk (because it is a persistent layer) before acknowledging the transaction commit. The log file sync wait event represents the time the session is waiting for the log buffers to be written to disk.
High “log file sync” can be observed in case of slow disk writes (LGWR takes long time to write), or because the application commit rate is very high. To identify a LGWR contention, examine the “log file parallel write” background wait event
Possible Causes:
Oracle foreground processes are waiting for a COMMIT or ROLLBACK to complete.
Action:
Tune LGWR to get good throughput to disk eg: Do not put redo logs on RAID5
Reduce overall number of commits by batching transactions so that there are fewer distinct COMMIT operations
log file parallel write:
Possible Causes:
LGWR waits while writing contents of the redo log buffer cache to the online log files on disk
I/O wait on sub system holding the online redo log files
Action:
Reduce the amount of redo being generated
Do not leave tablespaces in hot backup mode for longer than necessary
Do not use RAID 5 for redo log files
Use faster disks for redo log files
Ensure that the disks holding the archived redo log files and the online redo log files are separate so as to avoid contention
Consider using NOLOGGING or UNRECOVERABLE options in SQL statements.
free buffer waits:
Free buffer wait occurs when a user session reads a block from the disk and cannot find a free block in the buffer cache to place it in. This event can be caused by inappropriate Oracle setting (such as buffer cache size is too small for the load running on the system) or the DBWR (Database Writer) is unable to keep up with writing dirty blocks to the disks, freeing the buffer cache. In cases where free buffer wait is one of the dominant wait event, it is recommended to examine the disk performance (using iostat, perfmon etc.) and pay special attention to the performance of small random writes.
Possible Causes:
This means we are waiting for a free buffer but there are none available in the cache because there are too many dirty buffers in the cache
Either the buffer cache is too small or the DBWR is slow in writing modified buffers to disk
DBWR is unable to keep up to the write requests
Checkpoints happening too fast – maybe due to high database activity and under-sized online redo log files
Large sorts and full table scans are filling the cache with modified blocks faster than the DBWR is able to write to disk
If the number of dirty buffers that need to be written to disk is larger than the number that
DBWR can write per batch, then these waitscan be observed
Action:
Reduce checkpoint frequency - increase the size of the online redo log files
Examine the size of the buffer cache – consider increasing the size of the buffer cache in the SGA
Set disk_asynch_io = true set
If not using asynchronous I/O increase the number of db writer processes or dbwr slaves
Ensure hot spots do not exist by spreading datafiles over disks and disk controllers
Pre-sorting or reorganizing data can help
Direct path read:
Direct path read is an access path in which multiple Oracle blocks are read directly to the Oracle process memory without being read into the buffer cache in the Shared Global Area (SGA). This event is usually caused by scanning an entire table, index, table partition, or index partition during Parallel Query execution (although 11g support “direct path read” on serial scans).
Direct path read temp and direct path write temp:
Similar to Direct path read the Direct path read temp is an access path in which multiple Oracle blocks are read directly to the Oracle process memory without being read into the buffer cache in the Shared Global Area (SGA). The main difference between the two access paths is the source of data: in Direct path read temp the data is read from temporary tablespaces. This event is usually caused by a sort operation that cannot be complete in memory and requires storage access.
Direct path write temp is an access path in which multiple Oracle blocks are written directly to the temporary files by the shadow Oracle process.
Shared pool latch:
Possible Causes:
The shared pool latch is used to protect critical operations when allocating and freeing memory in the shared pool.
Contentions for the shared pool and library cache latches are mainly due to intense hard parsing. A hard parse applies to new cursors and cursors that are aged out and must be re-executed.
The cost of parsing a new SQL statement is expensive both in terms of CPU requirements and the number of times the library cache and shared pool latches may need to be acquired and released.
Action:
Ways to reduce the shared pool latch are, avoid hard parses when possible, parse once, execute many.
Eliminating literal SQL is also useful to avoid the shared pool latch. The size of the shared_pool and use of MTS (shared server option) also greatly influences the shared pool latch.
The workaround is to set the initialization parameter CURSOR_SHARING to FORCE. This allows statements that differ in literal values but are otherwise identical to share a cursor and therefore reduce latch contention, memory usage, andhard parse.
log file switch waits: mean that your sessions are directly waiting for LGWR, let’s see what LGWR itself is doing, by running snapper for 30 seconds on LGWR.
Additional points:
sequential writes are faster than random writes (which is definitely true for mechanical disks). Oracle writes the log file sequentially, while data blocks are written randomly.
Deploy custom JAR file
There are two ways to deploy custom JAR file:
Deploying on Custom path:
Steps:
1. Place JAR file at custom location "/u01/app/mahi/XX_TEST/"
2. Open “orion-application.xml” file present at path –
$ORA_CONFIG_HOME/10.1.3/j2ee/oacore/application-deployments/oacore/
3. Edit “orion-application.xml” file to add JAR file path
i.e. –
<library path="/u01/app/mahi/XX_TEST/jxl.jar" />
4. Bounce Apache Server
Deploying with Standard libraries.
1. Place jxl.jar into
$OA_HTML/WEB-INF/lib/
2. Bounce Apache Server
Deploying on Custom path:
Steps:
1. Place JAR file at custom location "/u01/app/mahi/XX_TEST/"
2. Open “orion-application.xml” file present at path –
$ORA_CONFIG_HOME/10.1.3/j2ee/oacore/application-deployments/oacore/
3. Edit “orion-application.xml” file to add JAR file path
i.e. –
<library path="/u01/app/mahi/XX_TEST/jxl.jar" />
4. Bounce Apache Server
Deploying with Standard libraries.
1. Place jxl.jar into
$OA_HTML/WEB-INF/lib/
2. Bounce Apache Server
Tuesday, July 18, 2017
rman:
Archivelog and Noarchivelog Modes:
Oracle writes all changes to the data blocks in memory to the online redo logs, usually before they are written to the database files. During a recovery process, Oracle uses the changes recorded in the redo log files to bring the database up-to-date. Oracle can manage the redo log files in two ways:
Archivelog mode: In this mode, Oracle saves (archives) the filled redo logs. Thus, no matter how old the database backup is, if you are running in archivelog mode, you can recover the database to any point in time using the archived logs. In this mode we can perform open backups—that is, backups while the database is running—only if the database is operating in archivelog mode.
Noarchivelog mode: In this mode, the filled redo logs are overwritten and not saved.In this mode thus implies that you can restore only the backup, and you’ll lose all the changes made to the database after the backup was performed.
Oracle backups is divided into logical and physical backups.
Logical Backup:
Logical backups are backups made using the Data Pump Export utility.
Physical backups refer to the backing up of the key Oracle database files: data files, archivedredo logs, and control files. Physical backups are made on disk or on tape drives.
Backup Levels:
Whole database:Back up all files including the control file. This level is applicable to both archivelog and noarchivelog modes of operation.
Tablespace backups:Back up all the data files belonging to a tablespace. Tablespace backups are applicable only in the archivelog mode.
Data file backups:Back up a single data file. Data file backups are valid in the archivelogmode only.
RMAN backups classification:
Full, Partial or incremental:
Open or closed:
Online or open (or hot/warm) backups are backups you make while the database is open and accessible to users.
Online backup not possible if the database is running in noarchivelog mode.
Closed (or clod) backup is made while the database is shut down. A closed backup is always consistent, as long as the database wasn’t shut down with the SHUTDOWN ABORT.Closed backups can be consistent or inconsistent.
Consistent or inconsistent:
Consistent:
consistent database means that the SCNs stored in all the data file headers are identical and are also the same as the data file header information held in the control files. The important thing is that the same SCN number must appear in all the data files and the control file(s).
Since the data is consistent, you don’t need to perform any recovery steps after you restore (or copy back) a set of backup files.
To make a consistent backup, either the database needs to be closed (with a normal SHUTDOWN
or SHUTDOWN TRANSACTIONAL command, not a SHUTDOWN ABORT command) or it needs to be in a mount position after being started (again, after a clean shutdown).
Inconsistent:
An inconsistent backup is a backup in which the files contain data from different points in
time. Inconsistent backups don’t mean there is anything wrong with your backups.However, during a recovery process, it isn’t sufficient to merely restore these backups. In addition to restoring these backups, you must also supply all archived and online redo logs from the time of the backup to the time to which you want to recover the database.
CHANNEL:
A channel is an RMAN server process started when there is a need to communicate with an I/O device, such as a disk or a tape. A channel is what reads and writes RMAN backup files.
OBSOLETE:
If a backup item is no longer needed for recovery – because it is older than the retention policy – then it is obsolete. A backup is obsolete if it’s no longer needed for database recovery, according to your retention policy.
DELETE OBSOLETE command will remove all backups you no longer need.
EXPIRED:
An expired backup means that the backup file can’t be found by RMAN but backup info holds in controlfile or catalog.
Run the CROSSCHECK command so RMAN can mark the backups it can’t find as expired and then use the DELETE EXPIRED command to remove the records for these files from the control file and the recovery catalog.
DELETE EXPIRED command removes the recovery catalog records for expired backups and marks them as DELETED.
Oracle writes all changes to the data blocks in memory to the online redo logs, usually before they are written to the database files. During a recovery process, Oracle uses the changes recorded in the redo log files to bring the database up-to-date. Oracle can manage the redo log files in two ways:
Archivelog mode: In this mode, Oracle saves (archives) the filled redo logs. Thus, no matter how old the database backup is, if you are running in archivelog mode, you can recover the database to any point in time using the archived logs. In this mode we can perform open backups—that is, backups while the database is running—only if the database is operating in archivelog mode.
Noarchivelog mode: In this mode, the filled redo logs are overwritten and not saved.In this mode thus implies that you can restore only the backup, and you’ll lose all the changes made to the database after the backup was performed.
Oracle backups is divided into logical and physical backups.
Logical Backup:
Logical backups are backups made using the Data Pump Export utility.
Physical backups refer to the backing up of the key Oracle database files: data files, archivedredo logs, and control files. Physical backups are made on disk or on tape drives.
Backup Levels:
Whole database:Back up all files including the control file. This level is applicable to both archivelog and noarchivelog modes of operation.
Tablespace backups:Back up all the data files belonging to a tablespace. Tablespace backups are applicable only in the archivelog mode.
Data file backups:Back up a single data file. Data file backups are valid in the archivelogmode only.
RMAN backups classification:
Full, Partial or incremental:
Open or closed:
Online or open (or hot/warm) backups are backups you make while the database is open and accessible to users.
Online backup not possible if the database is running in noarchivelog mode.
Closed (or clod) backup is made while the database is shut down. A closed backup is always consistent, as long as the database wasn’t shut down with the SHUTDOWN ABORT.Closed backups can be consistent or inconsistent.
Consistent or inconsistent:
Consistent:
consistent database means that the SCNs stored in all the data file headers are identical and are also the same as the data file header information held in the control files. The important thing is that the same SCN number must appear in all the data files and the control file(s).
Since the data is consistent, you don’t need to perform any recovery steps after you restore (or copy back) a set of backup files.
To make a consistent backup, either the database needs to be closed (with a normal SHUTDOWN
or SHUTDOWN TRANSACTIONAL command, not a SHUTDOWN ABORT command) or it needs to be in a mount position after being started (again, after a clean shutdown).
Inconsistent:
An inconsistent backup is a backup in which the files contain data from different points in
time. Inconsistent backups don’t mean there is anything wrong with your backups.However, during a recovery process, it isn’t sufficient to merely restore these backups. In addition to restoring these backups, you must also supply all archived and online redo logs from the time of the backup to the time to which you want to recover the database.
CHANNEL:
A channel is an RMAN server process started when there is a need to communicate with an I/O device, such as a disk or a tape. A channel is what reads and writes RMAN backup files.
If a backup item is no longer needed for recovery – because it is older than the retention policy – then it is obsolete. A backup is obsolete if it’s no longer needed for database recovery, according to your retention policy.
DELETE OBSOLETE command will remove all backups you no longer need.
EXPIRED:
An expired backup means that the backup file can’t be found by RMAN but backup info holds in controlfile or catalog.
Run the CROSSCHECK command so RMAN can mark the backups it can’t find as expired and then use the DELETE EXPIRED command to remove the records for these files from the control file and the recovery catalog.
DELETE EXPIRED command removes the recovery catalog records for expired backups and marks them as DELETED.
What is the difference between expired and obsolete backup?
Expire mean, the backup piece is not available at the physical location .
Obsolete backup mean, That backup piece is not required any more.
What is the difference between validate and crosscheck command?
Validate backup set – checks whether backup sets can be restored or not.
Crosscheck – go through the headers of the specified file, to check if they are on disk or tape.
Why are backups of a previous incarnation marked obsolete without regard to redundancy?
Can we restore a database from obsolete backup?
Yes we can restore a database from obsolete backup. For that we need to catalog those file explictly.
CATALOG START WITH command
RMAN> CATALOG START WITH '/disk1/backups/';
If you plan a database point in time recovery , you simply go
RMAN> run{set until time <time you like to go>; restore database;recover database;
RMAN> alter database open resetlogs;}
RMAN will then automatically use your obselete backup if needed . Obsolete does not mean expired. There is most likely no need to again catalog that backup.
Why are backups of a previous incarnation marked obsolete without regard to redundancy?
The incarnation is set to prevent you to restore backups that are too old. This way they are obsolete.
You can however still use them to restore but in that case you need to change the incarnation yourself to the 'previous' incarnation. At the same time your latest backups become obsolete.
Doc ID 206862.1 (How does the RMAN Retention Policy Obsolete Incremental Backupsets and Archivelog Files)
What is the purpose of resync catalog command?
Resynchronizing the Recovery Catalog and CONTROL_FILE_RECORD_KEEP_TIME
If you maintain a recovery catalog, then use the RMAN RESYNC CATALOG command often enough to ensure that control file records are propagated to the recovery catalog before they are reused.
Make sure that CONTROL_FILE_RECORD_KEEP_TIME is longer than the interval between backups or resynchronizations. Otherwise, control file records could be reused before they are propagated to the recovery catalog. An extra week is a safe margin in most circumstances.
What is the difference between maxpiece size and maxset size?
MAXPIECESIZE – Limits the size of each backup piece.
MAXSETSIZE – Maximum size of a backup set. Please remember, the maxsetsize value should be larger than the size of your largest data file.
Can i take the fullbackup from primary and incremental backup from standby?
Yes we can take backup from standby and primary database, as both the databases are same and have the same dbid.
Currently we have 30 days of archive logs present , so used delete archivelog all completed before ‘sysdate-3’ to delete files older than 3 days. But this command is not deleting files older than 14 days. Why?
You need to check your CONTROL_FILE_KEEP_RECROD_TIME. If this is set 14 days. then Only 14 days archive information will be stored in the control_file. If archive logs are older than 14 days, its related information will be removed from control_file.
So when we use rman it gets data from controlfile. As only 14 days information is present in control_file. RMAN delete command will ignore files older than 14 days.
Default value of CONTROL_FILE_KEEP_RECORD_TIME is 7 days.
Explain how rman works internally , when you are running rman database backup?
Lets say you connected as rman to target db and run backup database ;
rman target /
RMAN> backup database;
RMAN makes the bequeath connection with the target database.
It then connect to internal database user sys.RMAN and spawn multiple channel as mentioned in script.
Then RMAN make a call to sys.dbms_rcvman to request database schema information from controlfile( like datafile info,scn)
After getting the datafile list, it prepare for backup.To guarantee consistency it either builds or refreshes the snapshot control file.
Now RMAN make a call to sys.dbms_backup_restore package to create backup pieces.
If controlfile autobackup is set to on, then it will take backup of spfile and controfile to backupset.
During backup, datafile blocks are read into a set of input buffers, where they are validated/compressed/encrypted and copied to a set of output buffers. The output buffers are then written to backup pieces on either disk or tape (DEVICE TYPE DISK or SBT).
What are the different phases of RMAN backup.?
Read PhaseA channel reads blocks from disk into input I/O buffers.
Copy PhaseA channel copies blocks from input buffers to output buffers and performs additional processing on the blocks.
Write PhaseA channel writes the blocks from output buffers to storage media. The write phase can take either of the following mutually exclusive forms, depending on the type of backup media:
Who updates the block change tracking file(BCT) and how it does?
CTWR background process updates the block change tracking file.
REPORT SCHEMA command lists all data files that are part of the target database.
REPORT OBSOLETE command displays all the backups rendered obsolete based on the retention
policy.If there are obsolete backups in the repository, you can delete them with the DELETE OBSOLETE command.
REPORT NEED BACKUP command lists any data files that need backup to conform with the
retention policy you originally chose for your backups.
REPORT UNRECOVERABLE command lists all unrecoverable data files. An unrecoverable file
is a data file with a segment that has undergone a nologging operation, and should therefore be
backed up immediately.
LIST:
LIST BACKUP command shows you all the completed backups registered by RMAN. The
command shows all backup sets and image copies, as well as the individual data files, control files,
archived redo log files, and SPFILEs in the backup files. You can also list all backups by querying
V$BACKUP_FILES and the RC_BACKUP_FILES recovery catalog view.
LIST COPY command is analogous to the LIST BACKUP command and shows you the complete
list of all the copies made using RMAN.
LIST ARCHIVELOG ALL command will list all available archived log copies.
LIST SCRIPT NAMES command to display names of all the stored scripts
in the recovery catalog. The LIST GLOBAL SCRIPT NAMES command will show all the global scripts.
Difference b/w report and list :
Reporting list of files which need backup. RMAN Report command can be used to get a list of those datafiles which have not been backed up since last <n> days or to know which backupsets have become obsolete and can be deleted as per configured retention policy.
Example:
To know which files need backup since they have not been backed up since last 30 days give the following command
RMAN> report need backup days 2 database;
If you have configured the Retention Policy to redundancy 1. Then to know which backups have become obsolete and can be safely deleted, you can give a command as follows
RMAN> report obsolete
To know which database files require backup because they have been affected by some NOLOGGING operation such as a direct-path INSERT give the following command
RMAN> report unrecoverable;
List:You can view the information about backups you have taken using RMAN.
To view summary of database backups
RMAN> list backup summary;
To list details information about backupsets of database
RMAN> list backupset of database;
To list information about backupset of particular tablespace, you can give the following command
RMAN> list backupset of tablespace users;
To list information about particular datafile :
RMAN> list backup of datafile 4;
To list backup set by tag
LIST BACKUPSET TAG 'myfulldbbackup';
To list backup or copy by device type
LIST COPY OF DATAFILE '/u02/oracle/test/system01.dbf' DEVICE TYPE sbt;
To list backup by directory or path
LIST COPY LIKE '/u02/oracle/flash/%';
To list a backup or copy by a range of completion dates
LIST COPY OF DATAFILE 2 COMPLETED BETWEEN '01-OCT-2016' AND '31-OCT-2016';
Difference b/w report and list :
Reporting list of files which need backup. RMAN Report command can be used to get a list of those datafiles which have not been backed up since last <n> days or to know which backupsets have become obsolete and can be deleted as per configured retention policy.
Example:
To know which files need backup since they have not been backed up since last 30 days give the following command
RMAN> report need backup days 2 database;
If you have configured the Retention Policy to redundancy 1. Then to know which backups have become obsolete and can be safely deleted, you can give a command as follows
RMAN> report obsolete
To know which database files require backup because they have been affected by some NOLOGGING operation such as a direct-path INSERT give the following command
RMAN> report unrecoverable;
List:You can view the information about backups you have taken using RMAN.
To view summary of database backups
RMAN> list backup summary;
To list details information about backupsets of database
RMAN> list backupset of database;
To list information about backupset of particular tablespace, you can give the following command
RMAN> list backupset of tablespace users;
To list information about particular datafile :
RMAN> list backup of datafile 4;
To list backup set by tag
LIST BACKUPSET TAG 'myfulldbbackup';
To list backup or copy by device type
LIST COPY OF DATAFILE '/u02/oracle/test/system01.dbf' DEVICE TYPE sbt;
To list backup by directory or path
LIST COPY LIKE '/u02/oracle/flash/%';
To list a backup or copy by a range of completion dates
LIST COPY OF DATAFILE 2 COMPLETED BETWEEN '01-OCT-2016' AND '31-OCT-2016';
VALIDATE:
VALIDATE BACKUPSET command to validate backup sets before you use them from a
recovery.
RMAN Configuration:
SHOW ALL command to see the default values.
SELECT * FROM v$rman_configuration;
Backup Retention Policy:
A backup retention policy tells RMAN when to consider backups of data files and log files obsolete.RMAN only marks the file obsolete—it doesn’t delete it.
The REDUNDANCY Option:
The REDUNDANCY option lets you specify how many copies of the backups you want to retain.default is 1.
The RECOVERY WINDOW Option:
RECOVERY WINDOW option enables you to specify how far back in time you want to recover from when your database is affected by a media failure.
Default Device Type:
The default device for backups is disk;configure the default device type to sbt.
Degree of Parallelism:
The degree of parallelism (the default degree is 1) denotes the number of channels that RMAN can
open during a backup or recovery.
Connect to the catalog database and issue following query.
SQL> select name,dbid from rc_database;
What is the difference between physical and logical backups?
What is the significance of incarnation and DBID in the RMAN backups?
DBID stands for database identifier, which is a unique identifier for each oracle database running. It is found in control files as well as datafile header. If the database is open you can directly querying with the v$database and find the DBID. The DBID, which is a unique system-defined number given to every Oracle database, is what distinguishes one target database from another target database in the RMAN metadata.
SELECT DBID FROM V$DATABASE;
SELECT DB_KEY FROM RC_DATABASE WHERE DBID = dbid_of_target;
To obtain information about the current incarnation of a target database:
SELECT BS_KEY, BACKUP_TYPE, COMPLETION_TIME
FROM RC_DATABASE_INCARNATION i, RC_BACKUP_SET b
WHERE i.DB_KEY = 1
AND i.DB_KEY = b.DB_KEY
AND i.CURRENT_INCARNATION = 'YES';
When do you recommend hot backup? What are the pre-reqs?
When there is no down time for database (24/7) ,we should go for hot backup.
pre-req:database must be in archive log mode
How do you identify the expired, active, obsolete backups? Which RMAN command you use?
1) RMAN>crosscheck backup;This command will give you the output for the Active and Expired Backups.
2) RMAN>report obsolete;This command will shows you the obsolete backups.
How Recovery Manager Duplicates a Database?
To prepare for database duplication:
For the duplication to work, you must connect RMAN to both the target (primary) database and an auxiliary instance started in NOMOUNT mode.
Allocate at least one auxiliary channel on the auxiliary instance. The principal work of the duplication is performed by the auxiliary channel, which starts a server session on the duplicate host. This channel then restores the necessary backups of the primary database, uses them to create the duplicate database, and initiates recovery.
All backups and archived redo logs used for creating and recovering the duplicate database, however, must be accessible by the server session on the duplicate host.
As part of the duplicating operation, RMAN automates the following steps:
Creates a control file for the duplicate database.
Restores the target datafiles to the duplicate database and performs incomplete recovery by using all available incremental backups and archived redo logs.
Shuts down and starts the auxiliary instance.
Opens the duplicate database with the RESETLOGS option after incomplete recovery to create the online redo logs.
Generates a new, unique DBID for the duplicate database.
Renaming Database Files/Controlfiles/Redo logs/Temp files in RMAN Duplicate Database
• Renaming Control Files in RMAN DUPLICATE DATABASE
When choosing names for the duplicate control files, make sure you set the parameters in the initialization parameter file of the auxiliary database correctly; otherwise,
you could overwrite the control files of the target database.
• Renaming Online Logs in RMAN DUPLICATE DATABASE
RMAN needs new names for the online redo log files of the duplicate database. Either you can specify the names explicitly in the DUPLICATE command,
or you can let RMAN generate them according to the rules listed below:
Order Method Result
1 Specify the LOGFILE clause of DUPLICATE command. Creates online redo logs as specified.
2 Set LOG_FILE_NAME_CONVERT initialization parameter. Transforms target filenames, for example, from log_* to duplog_*. Note that you can specify multiple conversion pairs.
3 Set one of the Oracle Managed Files initialization parameters DB_CREATE_FILE_DEST, DB_CREATE_ONLINE_DEST_n, or DB_RECOVERY_FILE_DEST. Transforms target filenames based on the parameters set. The rules of precedence among these parameters are the same used by the SQL statement ALTER DATABASE ADD LOGFILE.
4 Do none of the preceding steps. Makes the duplicate filenames the same as the filenames from the target. You must specify the NOFILENAMECHECK option when using this method, and the duplicate database should be in a different host so that the online logs of the duplicate do not conflict with the originals.
• Renaming Datafiles in RMAN DUPLICATE DATABASE
There are several means of specifying new names to be used for the datafiles of your duplicate database. Listed in order of precedence, they are:
• Use the RMAN command SET NEWNAME FOR DATAFILE within a RUN block that encloses both the SET NEWNAME commands and the DUPLICATE command.
• Specify the DB_FILE_NAME_CONVERT parameter on the DUPLICATE command to specify a rule for converting filenames for any datafiles not renamed with SET NEWNAME or CONFIGURE AUXNAME.
Note:
The DB_FILE_NAME_CONVERT clause of the DUPLICATE command cannot be used to control generation of new names for files at the duplicate instance which are Oracle Managed Files (OMF) at the target instance.
• Set the DB_CREATE_FILE_DEST initialization parameter to create Oracle Managed Files datafiles at the specified location.
If you do not use any of the preceding options, then the duplicate database reuses the original datafile locations from the target database.
It is possible for SET NEWNAME, or DB_FILE_NAME_CONVERT to generate a name that is already in use in the target database. In this case, specify NOFILENAMECHECK on the DUPLICATE command to avoid an error message.
Renaming Tempfiles in RMAN DUPLICATE DATABASE
RMAN re-creates datafiles for temporary tablespaces as part of the process of duplicating a database. There are several means of specifying locations for duplicate database tempfiles. Listed in order of precedence, they are:
• Use the SET NEWNAME FOR TEMPFILE command within a RUN block that encloses both the SET NEWNAME commands and the DUPLICATE command.
W
Difference between catalog and nocatalog?
RMAN can be used for backup of oracle database in 2 modes.
1. NoCatalog mode
2. Catalog Mode
Recovery catalog is central and can have information of many databases.Here we need to create and maintain a seperate database for RMAN perpose.
In nocatalog mode the information regarding backup will be stored in target db control file. There is a limit to the amount of information can be stored in a control file.
Difference between using recovery catalog and control file?
When new incarnation happens, the old backup information in control file will be lost. It will be preserved in recovery catalog.
In recovery catalog, we can store scripts.
Recovery catalog is central and can have information of many databases.
Can we use same target database as catalog?
No. The recovery catalog should not reside in the target database (database to be backed up), because the database can't be recovered in the mounted state.
How do u know how much RMAN task has been completed?
By querying v$rman_status or v$session_longops
From where list & report commands will get input?
Both the commands command quering v$ and recovery catalog views. V$BACKUP_FILES or many of the recovery catalog views such asRC_DATAFILE_COPY or RC_ARCHIVED_LOG.
Command to delete archive logs older than 7days?
RMAN> delete archivelog all completed before sysdate-7;
What are the differences between crosscheck and validate commands?
Validate command is to examine a backup set and report whether it can be restored successfully where as crosscheck command is to verify the status of backup and
copies recorded in the RMAN repository against the media such as disk or tape.
You are working as a DBA and usually taking HOTBACKUP every night. But one day around 3.00 PM one table is dropped and that table is very useful then how will you recover that table?
If your database is running on oracle 10g version and you already enable the recyclebin configuration then you can easily recover dropped table from user_recyclebin or dba_recyclebin by using flashback feature of oracle 10g.
SQL> select object_name,original_name from user_recyclebin;
BIN$T0xRBK9YSomiRRmhwn/xPA==$0 PAY_PAYMENT_MASTER
SQL> flashback table table2 to before drop;
Flashback complete.
In that case when no recyclebin is enabled with your database then you need to restore your backup on TEST database and enable time based recovery for applying all archives before drop command execution. For an instance, apply archives up to 2:55 PM here.
It is not recommended to perform such recovery on production database directly because it is a huge database will take time.
Backup:
Incremental backups can be either level 0 or level 1. A level 0 incremental backup, which is the base for subsequent incremental backups, copies all blocks containing data, backing the datafile up into a backup set just as a full backup would. The only difference between a level 0 incremental backup and a full backup is that a full backup is never included in an incremental strategy.
A level 1 incremental backup can be either of the following types:
A differential backup, which backs up all blocks changed after the most recent incremental backup at level 1 or 0
A cumulative backup, which backs up all blocks changed after the most recent incremental backup at level 0
Which is one is good, differential (incremental) backup or cumulative (incremental) backup?
A differential backup, which backs up all blocks changed after the most recent incremental backup at level 1 or 0
A cumulative backup, which backs up all blocks changed after the most recent incremental backup at level 0
What level 0 and full backup:
The only difference between a level 0 incremental backup and a full backup is that a full backup is never included in an incremental strategy.
Full and level zero backups copy all blocks that have data (and more if you're doing image copies), so they are both "full" in that sense.
But if you want to do cumulative or differential backups, the starting point for those must be a level zero incremental backup.
What is Level 0, Level 1 backup?
A level 0 incremental backup, which is the base for subsequent incremental backups, copies all blocks containing data, backing the datafile up into a backup set just as a full backup would. A level 1 incremental backup can be either of the following types:
A differential backup, which backs up all blocks changed after the most recent incremental backup at level 1 or 0
A cumulative backup, which backs up all blocks changed after the most recent incremental backup at level 0
Can we perform level 1 backup without level 0 backup?
If no level 0 backup is available, then the behavior depends upon the compatibility mode setting. If compatibility < 10.0.0, RMAN generates a level 0 backup of the file contents at the time of the backup. If compatibility is >= 10.0.0, RMAN copies all blocks changed since the file was created, and stores the results as a level 1 backup. In other words, the SCN at the time the incremental backup is taken is the file creation SCN.
Will RMAN put the database/tablespace/datafile in backup mode?
Nope.
What is snapshot control file?
What is the difference between backup set and backup piece?
Backup set is logical,Backup sets, which are only created and accessed through RMAN, are the only form in which RMAN can write backups to media managers such as tape drives and tape libraries.
A backup set contains one or more binary files in an RMAN-specific format.
and backup piece is physical,
RMAN command to backup for creating standby database?
RMAN> duplicate target database to standby database ....
How to do cloning by using RMAN?
RMAN> duplicate target database …
Suppose you lost one datafile and DB is running in ARCHIVELOG mode. You have full database backup of 1 week/day old and don’t have backup of this (newly created) datafile. How do you restore/recover file?
create the datafile and recover that datafile.
SQL> alter database create datafile ‘…path..’ size n;
RMAN> recover datafile file_id;
What is the difference between hot backup & RMAN backup?
For hot backup, we have to put database in begin backup mode, then take backup.
RMAN won’t put database in backup mode.
How to put manual/user-managed backup in RMAN (recovery catalog)?
By using catalog command.
RMAN> CATALOG START WITH '/tmp/backup.ctl';
What are new features in Oracle 11g RMAN?
What is the difference between auxiliary channel and maintenance channel?
An auxiliary channel is a link to auxiliary instance. If you do not have automatic channels configured, then before issuing the DUPLICATE command, manually allocate at least one auxiliary channel within the same RUN command.
When a Duplicate Database created or tablespace point in time recovery is performed Auxiliary database is used. this database can either on the same host or a different host.
What are new features in Oracle 12c RMAN?
What is RAID? What is RAID0? What is RAID1? What is RAID 10?
RAID: It is a redundant array of independent disk
RAID0: Concatenation and stripping
RAID1: Mirroring
Backup Types:
Online/Hot/Inconsistent backup
Offline/Cold/Consistent Backup
Physical backup
Logical backup
Whole database backup
Incremental backup
Differential backup
Partial backup
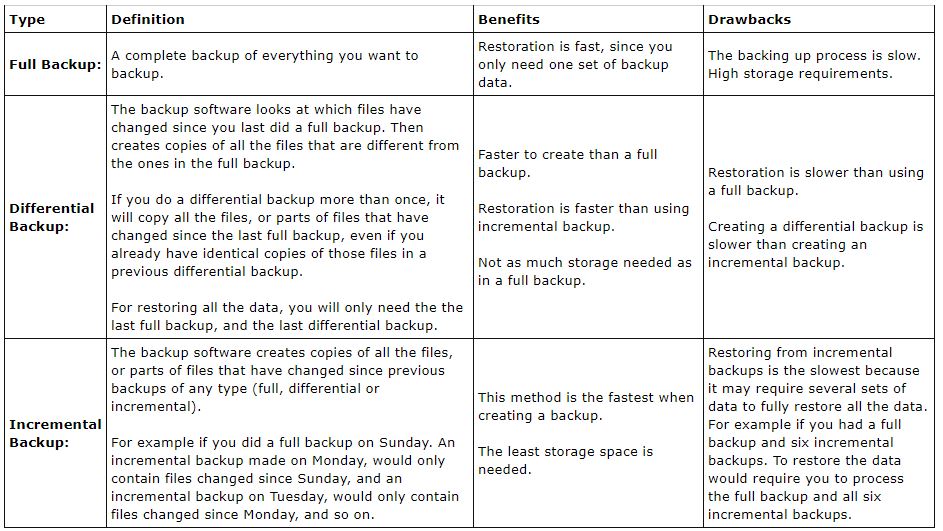
A database is running in NOARCHIVELOG mode then which type of backups you can take?
Offline/Cold/Consistent Backup
Can you take partial backups if the Database is running in NOARCHIVELOG mode?
No, Partial backup cannot take while database is not in archive log mode.
Can you take Online Backups if the database is running in NOARCHIVELOG mode?
No, we can’t take online backup while database is running in no archive log mode.A datafile that is backed up online will not be synchronized with any particular SCN, nor it will be synchronized with other data fileor the control files.
How do you bring the database in ARCHIVELOG mode from NOARCHIVELOG mode?
alter database noarchivelog;
archive log list;
You cannot shutdown the database for even some minutes, then in which mode you should run the database?
Database must be running in Archive log mode.
Can you take online backup of a Control file if yes, how?
alter database backup controlfile to trace;
alter database backup controlfile to ‘/oracle/app/ctrl.bak’;
Rman> backup current controlfile;
Rman> backup current controlfile to ‘/backup/ctrlfile.copy’;
Why do you take tablespaces in Backup mode?
The goal of ALTER TABLESPACE BEGIN BACKUP and END BACKUP is to set special actions in the current database files in order to make their copy usable , without affecting the current operations.
Nothing needs to be changed in the current datafile , but, as the copying is done by the external tool( Operating system utility), the only way to have something set in the copy is to do it in the current datafiles before the copy , and revert it back at the end.
Sql> alter tablespace begin backup;
While putting the tablespace in backup mode,
-the hot backup falg in the datafile header is set , so that the copy is identified to be a hot backup copy. This is to manage the backup consistency issue when the copy will be used for recovery.
- Checkpoint is done for the tablespace, so that in case of recovery , no redo generated before that point will be applied. Begin backup command completes only when checkpoint is done.
How do you see information about backups in RMAN?
To view summary of database backups
RMAN> list backup summary;
To list details information about backupsets of database you can give the following command
RMAN> list backupset of database;
To list information about backupset of particular tablespace,
RMAN> list backupset of tablespace users;
To list information about particular datafile
RMAN> list backup of datafile 4;
RMAN Report command can be used to get a list of those datafiles which have not been backed up since last <n> days or to know which backupsets have become obsolete and can be deleted as per configured retention policy
report obsolete
Can you take Image Backups using RMAN?
By default RMAN takes the backup as BACKUPSETS i.e. it combines of multiple datafiles into one or more backupsets.
If you want to take the backup of datafiles as it is then you can take IMAGE backups. To take image backups you have to mention 'AS COPY' option in backup command.
Let us take full database image backup using RMAN.
Now to take Full database IMAGE backup give the following command.
rman> backup as copy database tag 'MyFullImageBackup';
RMAN> backup as copy tablespace users;
RMAN> backup as copy datafile 2,6;
You have taken a manual backup of a datafile using o/s. How RMAN will know about it?
Using CATALOG to add their information to RMAN repository.
RMAN> catalog start with ‘d:\bak’;
You want to retain only last 3 backups of datafiles. How do you go for it in RMAN?
RMAN>configure retention policy to redundancy 3;
Subscribe to:
Comments (Atom)