Lock:
Lock is acquired when any process accesses a piece of data where there is a chance that another concurrent process will need this piece of data as well at the same time. By locking the piece of data we ensure that we are able to action on that data the way we expect.
For example, if we read the data, we usually like to ensure that we read the latest data. If we update the data, we need to ensure no other process is updating it at the same time, etc.
Locking is the mechanism that SQL Server uses in order to protect data integrity during transactions.
Block:
Block (or blocking lock) occurs when two processes need access to same piece of data concurrently so one process locks the data and the other one needs to wait for the other one to complete and release the lock.As soon as the first process is complete, the blocked process resumes operation. The blocking chain is like a queue: once the blocking process is complete, the next processes can continue. In a normal server environment, infrequent blocking locks are acceptable.
 Deadlock:
Deadlock:
Deadlock occurs when one process is blocked and waiting for a second process to complete its work and release locks, while the second process at the same time is blocked and waiting for the first process to release the lock.
 In a deadlock situation, the processes are already blocking each other so there needs to be an external intervention to resolve the deadlock. For that reason, SQL Server has a deadlock detection and resolution mechanism where one process needs to be chosen as the “deadlock victim” and killed so that the other process can continue working. The victim process receives a very specific error message indicating that it was chosen as a deadlock victim and therefore the process can be restarted via code based on that error message.
In a deadlock situation, the processes are already blocking each other so there needs to be an external intervention to resolve the deadlock. For that reason, SQL Server has a deadlock detection and resolution mechanism where one process needs to be chosen as the “deadlock victim” and killed so that the other process can continue working. The victim process receives a very specific error message indicating that it was chosen as a deadlock victim and therefore the process can be restarted via code based on that error message.
Deadlocks are resolved by SQL Server and do not need manual intervention.
Lock is acquired when any process accesses a piece of data where there is a chance that another concurrent process will need this piece of data as well at the same time. By locking the piece of data we ensure that we are able to action on that data the way we expect.
For example, if we read the data, we usually like to ensure that we read the latest data. If we update the data, we need to ensure no other process is updating it at the same time, etc.
Locking is the mechanism that SQL Server uses in order to protect data integrity during transactions.
Block:
Block (or blocking lock) occurs when two processes need access to same piece of data concurrently so one process locks the data and the other one needs to wait for the other one to complete and release the lock.As soon as the first process is complete, the blocked process resumes operation. The blocking chain is like a queue: once the blocking process is complete, the next processes can continue. In a normal server environment, infrequent blocking locks are acceptable.
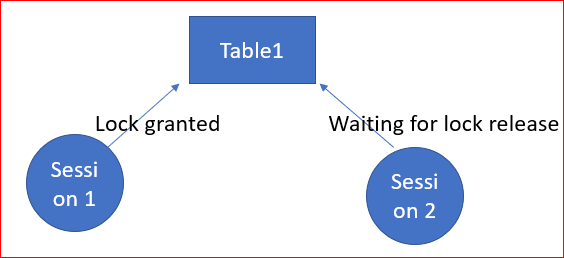
Deadlock occurs when one process is blocked and waiting for a second process to complete its work and release locks, while the second process at the same time is blocked and waiting for the first process to release the lock.

Deadlocks are resolved by SQL Server and do not need manual intervention.
No comments:
Post a Comment